


How a Realtime SMS Questions Service Scaled To Super Bowl Traffic with Rails
 When the UK-based Rails team at kgb was given ten weeks to scale their SMS question-answering "microwork" service for a Super Bowl ad, they didn't have much headroom left for more traditional Web scaling approaches. In this article, KGB developer J. Nathan Matias looks at how they prepared a high traffic Rails app to "scale down" during an expected rush of Super Bowl traffic.
When the UK-based Rails team at kgb was given ten weeks to scale their SMS question-answering "microwork" service for a Super Bowl ad, they didn't have much headroom left for more traditional Web scaling approaches. In this article, KGB developer J. Nathan Matias looks at how they prepared a high traffic Rails app to "scale down" during an expected rush of Super Bowl traffic.
Credit
J. Nathan Matias was a software engineer at the Knowledge Generation Bureau, where he wrote code to instrument, performance test, and scale their Rails-based SMS service until April 2010. A regular speaker at arts and technology events, he is also founder of the World University Project and has a passion for using technology to advance education and human understanding.
Intro
Our SMS question-answering "microwork" service (542 542) was already modular in a performance-friendly way (the subject of our RailsConf 2008 talk). Not much in our Turk-like answers system is cacheable. More mongrels would only overload our database. We didn't have time to shard. Our Super Bowl ad, the business told us, would generate two orders of magnitude greater volume than our historical peak. Over 100 million people would be watching, and nearly every text sent in by Super Bowl customers needed a human response!
With such a tight deadline, we needed two things above all: clarity about our goals, and good-enough solutions we could build in no time flat. Over the next few weeks, I'm going to be posting occasionally about what we did to scale our Rails apps for the Super Bowl. Where applicable, I'll try to include practical examples and insight from the experts at EngineYard, Percona, MX Telecom, and New Relic who helped us out.
Graceful Degradation on SMS Services
I'll write in later posts about what we did to measure and improve Rails performance. Yet even as we tried to scale our apps, we had to be prepared for the likelihood that those efforts wouldn't be enough. We had already run performance tests. We regularly keep an eye on our NewRelic instrumentation. Everything we knew about our architecture, MySQL scaling, and our apps' actual performance clearly put that our peak capacity far below the customer spikes we could expect from a Super Bowl ad.
On most web apps, when customer volume amps up beyond the capacity, the right response is usually graceful degradation -- serving simplified or reduced functionality to handle the load (c.f. Brewer's excellent "Lessons from Giant-Scale Services"). For noncritical areas, simply serve a fail whale and ask people to try again later. The servers can then breathe a little more freely to handle the important stuff.
These approaches work fine on the web, but are simply unacceptable for our realtime microwork service at kgb. For both web and SMS apps, response time is absolutely critical to customer satisfaction. Differences between these techs require different scaling approaches, and we work with both at the same time. Almost every SMS gets passed directly to our workers on the web, who we call "agents". An agent's response then travels from the web to the customer via SMS.
So for each question answered, we faced three scaling issues not commonly confronted on web-only apps:
- Incoming questions could exceed our agents' capacity to answer them
- System load from thousands of agents on our web app could hurt our ability to process incoming text messages, resulting in frustrated agents and dissatisfied customers
- Floods of incoming questions could slow down our answering app, spiralling down our agent efficiency. The growing backlog would further send our performance problems out of control
Choosing Graceful Degradation Approaches
Planning for graceful degradation requires a solid understanding of your system bottlenecks, your technical options for degrading, and your business requirements. Early on, we made a big list of everything we could simplify or turn off. I think these examples represent the kind of choices anyone might face in a similar situation:
The first approach is to simplify the interface. Since SMS is plaintext, we couldn't simplify our SMS frontend any further. On the web side, we didn't have time to retrain our agents on a simpler UI. Turning off interface elements is easy with our modular architecture (talk | github). But some of our most expensive controller actions actually reduce system load -- by taking one request to do several jobs.
Nor can we resort to fail whales and simply turn things off. Mobile carrier policies and government regulations require our service to step through dances such as "opt-in" and "opt-out", two common billing protocols where positive confirmation is required for customers of paid SMS services. The SMS equivalent of a 503 error when a user tries to cancel the service could give us problems with the carriers or a regulation authority. 503s were also unacceptable on the web; they would simply increase the risk of falling behind customer demand.
Instead of radically changing the interface or sending out error messages, we focused on alternative logic for our controllers which could be activated without a restart. For example, we could reduce agents' choice over which questions to answer. Agents might be less happy and we might face other product tradeoffs but our overall service would be healther. Some parts of the system, like the model which verifies that answers meet business rules, had to remain untouched. Our very last resort would be to automatically log out a percentage of random agents.
Unlike many traffic spikes, we knew when this one would happen, and when it would probably end. So we could safely turn off nonessentials, such many of our cron jobs, business reports, and the AI which schedules our shifts.
Using Daemons to Make Scaling Decisions
On some ideal imaginary service, graceful degradation is like peeling an onion. As things get worse, you keep peeling away the least important layer of service. For our system, with its competing risks from human and system capacities, we needed quick decisions from a complex mix of factors. Some decisions absolutely require human decisions, and we built a dashboard for making them. But we put as much power as possible into a ruby daemon we built to keep track of our system and make those decisions itself.
If you're not familiar with Rails daemons or how to write one, you can check out Railscast #129: Custom Daemon, or Tammer Saleh's great slides -- "Angels and Daemons" -- from RailsConf 2007 for an overview.
In most cases, you probably shouldn't focus your daemon on system monitoring. It's probably much better to base decisions on simple business reports. Rules like this don't make sense if you're planning to run hot:
- If the database load average is too high, kick agents off the system to cool things down
In contrast: rules like these make sense as business decisions:
- If most questions are taking too long to answer, send apologies about the wait
- If messages are sending at too low a rate, turn off or delay some outgoing message types
Seriously - resist the temptation to waste your time writing a system monitoring daemon. System metrics are simply not specific enough, and they say nothing about what will happen next. Look at what happened to us on Super Bowl Sunday:
- Within seconds of our TV ad, we were slammed by a massive spike of incoming messages
- Our servers soon hit their peak capacity for receiving questions, which started to pile up outside our system
- The rate of incoming messages was well over our agents' answer rate
- Load average on the servers was freaking out
- Under the load, response times slowed down to more than twice their healthy average
If you expect the system to reach its peak performance, system metrics only show you what you expect: that the system is struggling. System load information can't tell you what part of your app is suffering. Response times are more specific, but momentary bottlenecks in one controller might be caused by an ugly query somewhere else. Result: needless panic.
In contrast, decisions based on business metrics can focus on your actual experience and business priorities. We already knew the shape of TV-driven volume from our other ads. So we expected a spike of traffic which would tail off gently. If questions came in faster than we could answer them, we wanted to deal with the spike as quickly as possible by pushing the system as hard as it could go.
On Super Bowl Sunday itself, a trigger-happy monitoring daemon could have kept our servers happy but delivered a bad customer experience. Instead, our business-focused rules held their fire. The backlog of questions nearly reached the decision threshholds, and then returned to safe levels as the spike tailed off. Job done.
SMS Steam Valves
The SMS nature of our business could have been our demise. In this case, I think it played in our favour, smoothing out the traffic spike and giving us one last resort for fault tolerance.
Most webservers have the luxury of a logical connection to the client. On SMS, we must deal with a highly asynchronous client interaction in exchange for the ability to charge micropayments. On Super Bowl day, we expected this nasty gang of issues to stand in the way of good customer experience:
- We can't know how long it took for a message to reach us, since SMS doesn't consistently timestamp the message origin
- Some carriers don't tell us how long a message takes to reach our customer, although we are eventually told if it arrived
- We switched off those SMS delivery reports for some carriers to gain extra capacity, so we wouldn't know until later if our messages had arrived
- We should be prepared for mobile networks ( which famously run close to capacity ) to have throughput problems, even outages
- Mobile network outages tend to hit our system hard. As soon as the carrier fixes something, our system gets slammed by the backlog of messages
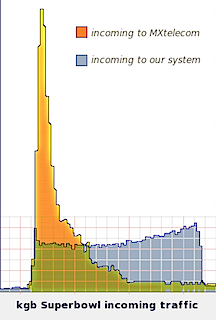
All of these risks were amplified on Super Bowl Sunday. We were spending a lot of money on ads which touted the speed of our service-- on the day when network reliability is least knowable. If a message takes ten minutes to reach us, the customer is already lost before we start. Without any record of send time, we have no easy way to prioritise service. Even if our star agents fired out super-speed texts of pure enlightenment, our perfect answers might limp along with Kafkaesque inefficiency.
On the other hand, the complexities of mobile networks gave us a great last-resort load balancing option. Each carrier's network is a bit different, so we use an SMS gateway by MX Telecom. They manage our connections to the networks; we simply send and receive messages via a web service. MX queued our incoming and outhoing messages to smooth out our connection to the carriers. Then, if our systems were well and truly up against the wall, MX could turn on a simple Super Bowl SMS quiz to save customers and give our servers a break.
As you can see in this graph, the queuing at MX Telecom made it possible for us to survive the customer onslaught. Delays are bad for customer satisfaction, but we were also trying to prevent too much volume from overloading our servers. SMS network latency also probably helped us. Between the queuing and SMS latency on Super Bowl Sunday, the load was smoothed out just enough to make the last resort unnecessary.
Comments & Upcoming Posts
Please ask questions in the comments area-- I'll keep an eye out and answer what I can. I had planned for the next post to discuss refactoring your architecture for scalability. But this post is pretty concept heavy, so I think the next one will give practical tips on performance testing.







March 24th, 2010 at 1:54 am
This may not apply entirely but I'd recommend TourBus (http://github.com/dbrady/tourbus) which provides a good way of combining load testing and integration testing.
March 29th, 2010 at 4:08 pm
Interested in what we do at kgb? Our tech team now has a website, and we're hiring in Cardiff and Cambridge UK. Check us out at http://kgbwizards.com